Kubernetes client-go 源码解析——WorkQueue
Contents
WorkQueue称为工作队列,支持如下的特性:
- 有序:按照添加顺序处理元素
- 去重:相同元素在同一时间不会被重复处理,例如一个元素在处理之前被添加了多次,它只会被处理一次。
- 并发性:多生产者与多消费者。
- 标记机制:支持标记功能,标记一个元素是否被处理,也允许元素在处理时重新排队。
- 通知机制:
ShutDown方法通过信号量通知队列不再接收新的元素,并通过metric goroutine退出。 - 延迟:支持延迟队列,延迟一段时间后再将元素存入队列。
- 限速:支持限速队列,元素存入队列时进行速率限制。限制一个元素被重新排队的次数。
- Metric:支持metric监控指标,可用于Prometheus监控。
WorkQueue支持3种队列,并提供了3种接口,不同队列实现可应对不同的使用场景:
Interface:FIFO队列接口,支持去重机制。DelayingInterface:延迟队列接口,基于Interface封装,延迟一段时间后再将元素存入队列。RateLimitingInterface:限速队列接口,基于DelayingInterface封装,支持元素存入队列时进行速率限制。
FIFO队列
此部分代码实现位于util/workqueue/queue.go中。首先,client-go定义了一个Type类型作为FIFO队列的数据结构实现。
1 | type Type struct { |
一些重要字段的含义如下:
queue:包含按照顺序需要处理的事件。类型t只是一个别名type t interface{}。其本质的目的在于用于保证元素的有序。dirty:包含所有需要处理的事件,按照这个定义所有在queue的事件必然在dirty中。类型set也是一个别名type set map[t]empty,empty也是一个别名,type empty struct{}。既保证了去重,还能保证在处理一个元素之前哪怕其被添加了多次,但也只会被处理一次。processing:包含正在处理的事件。dirty也可能包含某些processing中的事件。cond:条件变量。shuttingDown:是否关闭队列。drain:关闭队列时是否立即消耗完仍然存在的元素。metrics:指标接口,定义在util/workqueue/metrics.go。unfinishedWorkUpdatePeriod:每次时钟更新的时间,用于初始化时钟。clock:时钟。
然后,client-go定义了用于FIFO队列的接口Interface。
1 | type Interface interface { |
Add:给队列添加元素。Len:返回当前队列的长度。Get:获取队列头部的一个元素。Done:标记队列中该元素已被处理。ShutDown:关闭队列。ShutDownWithDrain:关闭队列并立即处理完在processing中的元素。ShuttingDown:查询队列是否正在关闭。
为了更好地理解FIFO队列,我们首先对两个场景进行描述。一个场景是无并发环境,一个是存在并发的环境。
场景一:通过Add方法往FIFO队列中分别插入1、2、3三个元素,此时队列中的queue和dirty字段分别存有1、2、3元素,processing字段为空。元素1被放入processing字段,表示该元素正在被处理。最后,当处理完1元素时,通过Done方法标记该元素已经处理完成,此时队列中的processing字段中的1元素会被删除。
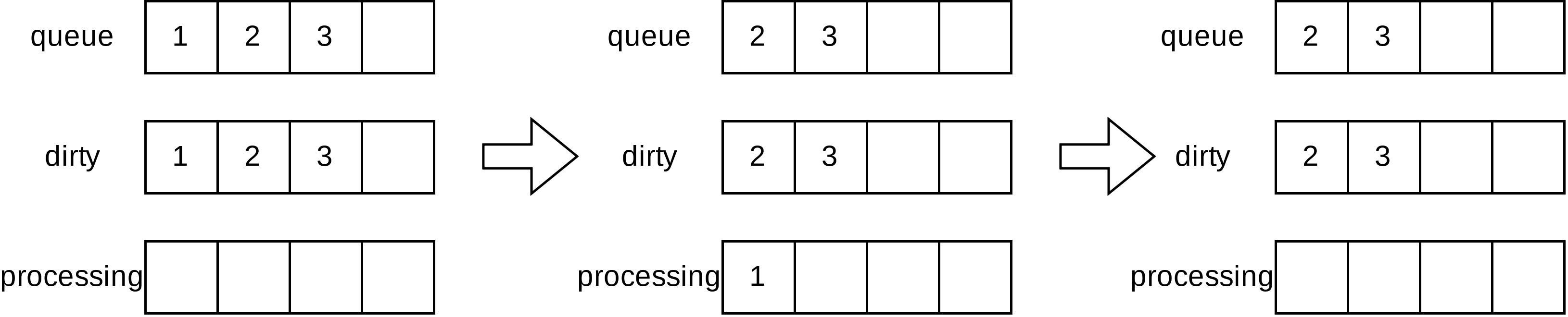
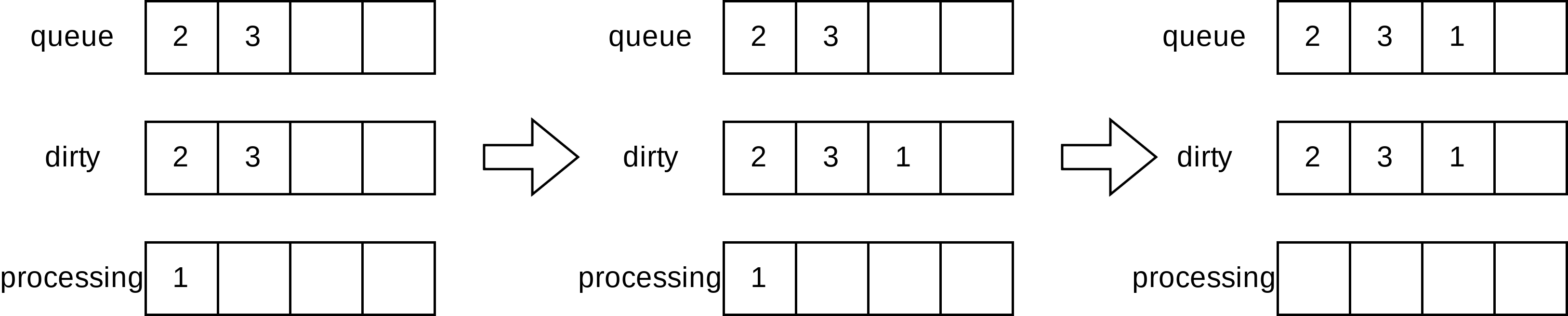
场景二:在并发场景下,假设goroutine A通过Get方法获取1元素,1元素此时被添加到processing字段中,同一时间,goroutine B通过Add方法插入另一个元素,由于processing已经有元素1,故不会存入queue中而是存入dirty中。当元素1处理完成后,则将1元素追加到queue字段中的尾部。
队列初始化及其生命周期
queue.go首先定义了一个辅助函数updateUnfinishedWorkLoop用于对整个队列的生命周期进行管理。
1 | func (q *Type) updateUnfinishedWorkLoop() { |
该方法利用for range t.C(),每隔q.unfinishedWorkUpdatePeriod秒,都会判断队列是否被关闭,如果队列没有被关闭,则返回true,继续执行循环。如果队列被关闭,则直接返回false,然后退出循环,结束函数执行。
然后是对其进行初始化。首先定义了一个基本的New函数。然后层层抽象。
1 | func New() *Type { |
其中,defaultUnfinishedWorkUpdatePeriod只是一个常量。
1 | const defaultUnfinishedWorkUpdatePeriod = 500 * time.Millisecond |
然后就是最关键的就是newQueue函数。
1 | func newQueue(c clock.WithTicker, metrics queueMetrics,updatePeriod time.Duration) *Type { |
可以看见,当定义了一个FIFO队列后,updateUnfinishedWorkLoop将会一直运行然后每隔一定的时间检测队列的shuttingDown的值。可见,利用该值作为信号来传递。
set方法定义
为了更加方便地对set,即map[t]empty类型进行操作。queue.go定义了一系列方法简化,把基本的map方法封装了一下。
1 | func (s set) has(item t) bool{ |
Type方法定义
首先是实现Interface的Add方法。
1 | func (q *Type) Add(item interface{}) { |
为了保持互斥首先需要上锁,然后判断队列是否已经被关闭。如果没有被关闭,首先添加到dirty中,然后判断item是否位于processing中,如果没有添加到queue中。然后释放信号用于同步。这是一个典型的生产者与消费者的问题。生产者是Add方法,消费者是Get方法。
同样实现Interface的Len方法。很简单,加个锁即可。
1 | func (q *Type) Len() int { |
然后实现Interface的Get方法。
1 | func (q *Type) Get() (item interface{}, shutdown bool) { |
显然,Get方法作为一个消费者当队列为空时,应该等待故调用了q.cond.Wait。然后取出第一个元素,置queue[0]为空以便进行垃圾回收,插入到processing中,然后从dirty中删除。
Done方法用于告知队列该元素已被处理,如果该元素存在dirty中,我们需要将其重新加入到queue中来处理。
1 | func (q *Type) Done(item interface{}) { |
ShutDown方法让队列忽略所有需要新增的item然后立即告知worker goroutine退出。
1 | func (q* Type) ShutDown() { |
定义了两个辅助函数setDrain和shutdown进行抽象。
1 | func (q* Type) setDrain(shouldDrain bool) { |
注意q.cond.Broadcast的使用,尽管关闭了队列,但我们仍然可以使用Get方法去获取元素。可能此时q.queue有元素或者没有,但我们必须使用避免阻塞了其他函数。
然后queue.go定义了ShutDownWithDrain关闭队列并立即处理q.queue中的元素。
1 | func (q *Type) ShutDownWithDrain() { |
同步机制总结
在FIFO队列中,存在许多同步的东西,总结如下:
- 基本的生产者-消费者模型。
Add方法需要调用q.cond.Signal通知等待的Get方法。Done方法可能也会添加新的item。故如果新增了新的item,也需要调用q.cond.Signal通知等待的Get方法。 Done方法在q.processing.len() == 0时也会调用q.cond.Signal实现同步,这是因为ShutDownWithDrain方法会调用waitForProcessing然后再调用q.cond.Wait阻塞自身。显然对于drain来说,开发者必须对每个方法item调用Done方法,以便在q.processing的长度为0时,唤醒ShutDownWithDrain方法。
指标
指标定义在metrics.go中,可以看见我们在处理item的时候,也会对其的指标进行操作,由于该部分不是核心代码,此处不进行分析。
延迟队列
此部分代码定义在util/workqueue/delaying_queue.go中。延迟队列基于FIFO队列接口封装,在原有的功能上增加了AddAfter方法。
1 | type DelayingInterface interface { |
我们首先看延迟队列的AddAfter方法是如何实现的:
1 | func (q *delayingType) AddAfter(item interface{}, duration time.Duration) { |
很明显,这个函数就做了一个极其简单的事情,当duration小于0时,直接加入队列中。
我们首先需要看delayingType这个类型:
1 | type delayingType struct { |
一些重要的字段含义如下:
stopCh:利用channel作信号量。stopOnce:只能Stop一次。waitingForAddCh:用来存储待加入的item。
其中waitFor的类型定义如下:
1 | type waitFor struct { |
代码维护了一个优先队列waitForPriorityQueue,其本质的思路在于实现heap的接口,内容比较简单,此处忽略细节。
newDelayingQueue函数创建了一个新的延迟队列,然后启用waitingLoop goroutine。
1 | func newDelayingQueue(clock clock.WithTicker, q Interface, name string) *delayingType { |
waitingLoop是延迟队列实现的核心所在。其本质的思路仍然是实现同步,此处忽略细节。
限速队列
限速队列在延迟队列接口的基础上增加了AddRateLimited, Forget, NumRequeues方法:
1 | type RateLimitingInterface interface { |
然而这三个方法都是调用RateLimiter的接口方法:
1 |
|
When:获取指定元素应该等待的时间。Forget:释放指定元素。NumRequeues:返回元素的失败数。
WorkQueue提供了4种限速算法:
- 令牌桶算法:下节单独介绍
- 排队指数算法:将相同元素的排队数作为指数,排队数增大,速率限制呈指数级增长。
- 计数器算法:限制一段时间内允许通过的元素数量。
- 混合模式
令牌桶
client-go使用令牌桶作为限流算法。
Limiter数据结构定义
Go语言标准库提供了令牌桶算法的实现。首先在rate.go中定义了Limiter。
1 | type Limiter struct { |
其中Limit仅仅只是一个类型Wrapper:type Limit float64。字段的含义如下:
mu:互斥锁limit:每秒下发令牌的个数burst:桶的最大令牌数量tokens:当前令牌数量last:最后一次tokens字段更新时间lastEvent:最近一次限流事件发生的时间
目前limit的定义为每秒下发令牌的个数,故rate.go定义了Every函数将事件之间的最小时间间隔转换为Limit。当limit = Inf时,burst可以被忽略,允许任何事件通过,因为下发令牌的个数是无限的。同时,limit也可以为0,代表不允许任何事件通过。
1 | func Every(interval time.Duration) Limit { |
rate.go定义了一些基本的getter和setter方法。
1 | func (lim *Limiter) Limit() Limit { |
辅助函数
为了更加好的抽象,rate.go定义了一系列的辅助函数。根据令牌桶的概念我们可以知道,随着时间的变化,令牌桶中的令牌数量会增加。故为了实现时间间隔和令牌桶的令牌数量相互的转化,rate.go定义了tokensFromDuration和durationFromTokens。
1 | // 得到一个时间段会产生多少个令牌 |
随着时间的变化,需要对令牌桶中的令牌也就是token进行更新,故定义了advance函数。
1 | func (lim *Limiter) advance(now time.Time) (newNow time.Time, newLast time.Time, newTokens float64) { |
方法
Limiter还包含一些setter方法,介绍了辅助函数后,对于这些setter方法就比较容易理解。
1 | func (lim *Limiter) SetLimit(newLimit Limit) { |
Limiter主要有三个方法:Allow, Reserve和Wait。这三个方法在被调用时,都会消耗掉一个令牌。这三个方法分别被AllowN,ReserveN以及WaitN抽象。
1 | func (lim *Limiter) Allow() bool { |
首先,rate.go定义了Reservation数据结构,包含了已经被限流器所允许的事件的信息。
1 | type Reservation struct { |
字段的含义如下:
ok:表示事件能否发生lim: 属于哪个Limitertokens:表示该事件需要消耗的令牌数量timeToAct:执行的时间limit:在Reserve操作的时候定义
我们首先看函数AllowN。
1 | func (lim *Limiter) AllowN(now time.Time, n int) bool { |
再看函数ReserveN
1 | func (lim *Limiter) ReserveN(now time.Time, n int) *Reservation { |
可以看出AllowN和ReserveN都是通过reserveN进行抽象的。首先reserveN处理特殊情况,即limit = Inf(允许任何事件通过)和limit = 0(不允许任何事件通过),虽然不允许任何事件通过,但是本身令牌桶初始化時有burst个令牌数,故还是可以允许通过burst个令牌。
再处理完特殊情况后,首先通过advance计算出现在时刻的令牌桶中的令牌数量的个数,减去该事件所消耗的令牌个数。当令牌数小于0证明该事件需要等待,故通过durationFromTokens计算需要等待的时间。
其次,判断事件能否发生。事件能发生需要满足两个条件,一是事件发生消耗的令牌数量不能超过令牌桶最大的令牌数量,二是等待时间不能超过参数maxFutureReserve的值。
后面的操作就是更新字段。
1 | func (lim *Limiter) reserveN(now time.Time, n int, maxFutureReserve time.Duration) Reservation { |
可以看出reserveN作为一个核心的函数,无非就是查询令牌桶中的令牌数量足不足以支持一个消耗n个令牌的任务,为了维持这个任务的状态必须定义一个数据结构来维持。
在讲WaitN函数之前,我们先看看DelayFrom函数,这个函数很简单,对于已经ok的任务,得到其延迟发生的时间。
1 | func (r *Reservation) DelayFrom(now time.Time) time.Duration { |
现在我们可以去看WaitN函数,很显然对于一个任务来说,其可以通过调用WaitN来实现限流。
- 当所需的令牌数目大于令牌桶所能包含的最大令牌,直接返回error。
- 如果在调用时,任务已经结束了,直接返回error。
- 计算
waitLimit其值为任务结束的时间和现在的时间的差值,然后使用reserveN得到任务的状态。 - 然后使用
DelayFrom计算需要延迟的时间,如果有必要延迟的话,通过一个定时器来延时。如果定时器完成了,就继续。如果定时器结束之前,Context被取消了,返回错误。
1 | func (lim *Limiter) WaitN(ctx context.Context, n int) (err error) { |
注意r.Cancel()的使用,既然我们已经给了令牌给一个任务而这个任务并没有实际的执行,我们应该还给令牌桶相应的数目。由于此时已经介绍了大部分的函数,此处忽略其细节。
小结
令牌桶的实现与时间有很大的关系,看似需要每隔1s就需要更新令牌桶中的令牌数目,实则上是完全没有必要的。因为可以从未来借。当每一次调用主要方法时,都会通过现在的时间减去上一次令牌桶数目更新的时间来更新令牌桶中的令牌数目,令牌桶中的令牌数目是负的也根本无所谓,很棒的设计。
Client-go封装
Client-go在util/workqueue/default_rate_limiters.go中定义了BucketRateLimiter用于封装标准库中的Limiter。
1 | type BucketRateLimiter struct { |