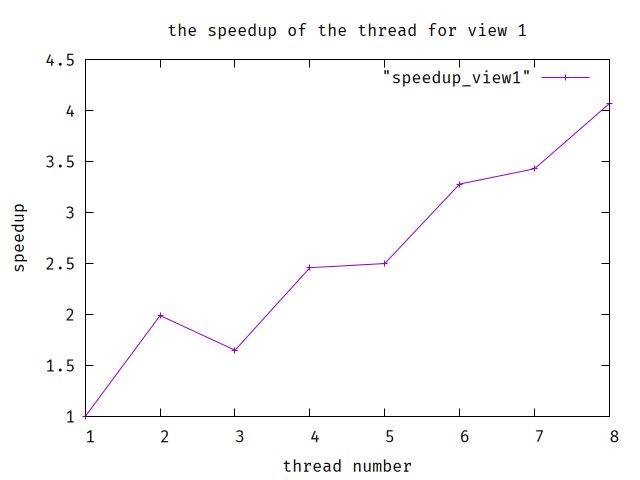
set title "the speedup of the thread for view 1" set xlabel "thread number" set ylabel "speedup" plot "speedup_view1" w lp set terminal pngcairo set output "The speedup for view 1.png" replot set terminal qt set output
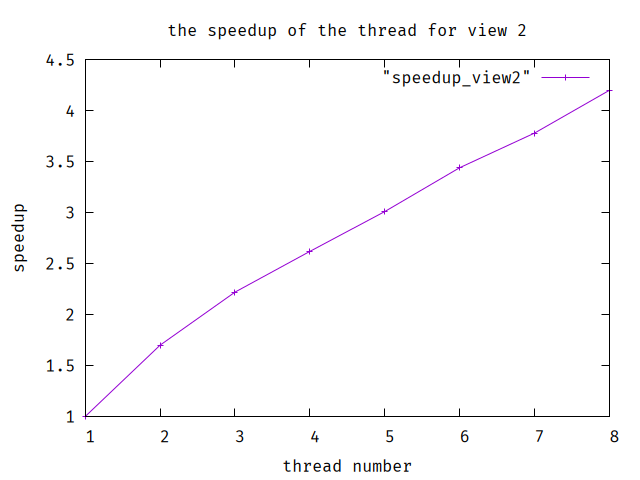
By the way, I also plot the speedup for view 2.
As this two picture shows, we can find that the speedup for view 2 is nearly linear but not for view 1. The reason is the imbalance of the data. For view 1, some threads handle more data but some handle little, and we still need to wait for all threads which wastes lots of time.
Question 1.3
Question 1.4
The most important thing to do is to balance the load. But we don’t know the actual load, so we should make slice for each thread job. Don’t let a thread do a consecutive area. Just handle only one raw.
It’s not, the reason is because that the Amdahl’s law. Which says that if a fraction $r$ of the serial program remain unparallelizm we can’t get a speedup better than $1/r$. In this example, we have an important serial function mandelbrotSerial, so we can guess the value of $r$ to be 0.9 (I guess). So no matter how many threads we create, we could not get a speedup better than 9.
Program 2
This program is aimed at using SIMD. However, I have learned some basic ideas in CS61C.
intclampedExpVectorHelper(float* values, int* exponents, float* output, int N){ __cs149_vec_float x; __cs149_vec_int y; __cs149_vec_float result; __cs149_vec_int zero = _cs149_vset_int(0); __cs149_vec_int one = _cs149_vset_int(1); __cs149_vec_float max = _cs149_vset_float(9.999999f); __cs149_mask maskAll, maskIsExponentZero; __cs149_mask maskIsNotExponentZero, loop, isExceedMax;
int i = 0 ; for(;i + VECTOR_WIDTH <= N; i += VECTOR_WIDTH) { maskAll = _cs149_init_ones(); isExceedMax = _cs149_init_ones(0);
result = _cs149_vset_float(0.0f); _cs149_vload_int(y, exponents + i, maskAll); _cs149_veq_int(maskIsExponentZero, y, zero, maskAll); _cs149_vset_float(result, 1.f, maskIsExponentZero);
maskIsNotExponentZero = _cs149_mask_not(maskIsExponentZero); _cs149_vload_float(x, values + i, maskIsNotExponentZero); _cs149_vadd_float(result, result, x , maskIsNotExponentZero); _cs149_vsub_int(y, y, one, maskIsNotExponentZero); _cs149_vgt_int(loop, y, zero, maskIsNotExponentZero); while(_cs149_cntbits(loop) != 0) { _cs149_vmult_float(result, result, x , loop); _cs149_vsub_int(y, y, one, loop); _cs149_vgt_int(loop, y, zero, loop); } _cs149_vgt_float(isExceedMax, result, max, maskIsNotExponentZero); _cs149_vset_float(result, 9.999999f, isExceedMax);
_cs149_vstore_float(output + i, result, maskAll); } return i; }
voidclampedExpVector(float* values, int* exponents, float* output, int N){
int index = clampedExpVectorHelper(values, exponents, output, N);
if(index != N ) { float valuesTemp[VECTOR_WIDTH] {}; int exponentsTemp[VECTOR_WIDTH] {}; float outputTemp[VECTOR_WIDTH] {}; for(int i = index; i < N; ++i) { valuesTemp[i - index] = values[i]; exponentsTemp[i - index] = exponents[i]; } clampedExpVectorHelper(valuesTemp, exponentsTemp, outputTemp, VECTOR_WIDTH); for(int i = index ; i < N; ++i) { output[i] = outputTemp[i - index]; } } }
Question 2.2
When the vector width is 2:
1 2 3 4 5
Vector Width: 2 Total Vector Instructions: 167727 Vector Utilization: 77.3% Utilized Vector Lanes: 259325 Total Vector Lanes: 335454
When the vector width is 4:
1 2 3 4 5
Vector Width: 4 Total Vector Instructions: 97075 Vector Utilization: 70.2% Utilized Vector Lanes: 272541 Total Vector Lanes: 388300
When the vector width is 8:
1 2 3 4 5
Vector Width: 8 Total Vector Instructions: 52877 Vector Utilization: 66.5% Utilized Vector Lanes: 281229 Total Vector Lanes: 423016
When the vector width is 16:
1 2 3 4 5
Vector Width: 16 Total Vector Instructions: 27592 Vector Utilization: 64.8% Utilized Vector Lanes: 285861 Total Vector Lanes: 441472
As you can see, the vector utilization decreases, the reason I think is that the branch we make in each vector, when the vector size becomes bigger, the branch is more likely.
Question 2.3
It’s easy.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
floatarraySumVector(float* values, int N){ float value[VECTOR_WIDTH] {}; __cs149_vec_float sum = _cs149_vset_float(0.0f); __cs149_vec_float num; __cs149_mask maskAll = _cs149_init_ones(); for (int i=0; i<N; i+=VECTOR_WIDTH) { _cs149_vload_float(num, values + i, maskAll); _cs149_vadd_float(sum, sum, num, maskAll); } int number = VECTOR_WIDTH; while (number /= 2) { _cs149_hadd_float(sum, sum); _cs149_interleave_float(sum, sum); } _cs149_vstore_float(value, sum, maskAll); return value[0]; }
Program 3
Part I
We should first understand the code mandelbrot_ispc.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
export void mandelbrot_ispc(uniform float x0, uniform float y0, uniform float x1, uniform float y1, uniform int width, uniform int height, uniform int maxIterations, uniform int output[]) { float dx = (x1 - x0) / width; float dy = (y1 - y0) / height;
foreach (j = 0 ... height, i = 0 ... width) { float x = x0 + i * dx; float y = y0 + j * dy;
int index = j * width + i; output[index] = mandel(x, y, maxIterations); } }
The idea here is obvious. We could split the graph into man $1 \times 1$ squares. And use 8-vector to solve. So the speedup should be 8. However the result is below.
1 2 3 4 5 6 7 8 9 10 11 12
# ./mandelbrot_ispc -v 1 [mandelbrot serial]: [175.258] ms Wrote image file mandelbrot-serial.ppm [mandelbrot ispc]: [30.405] ms Wrote image file mandelbrot-ispc.ppm (5.76x speedup from ISPC) # ./mandelbrot_ispc -v 2 [mandelbrot serial]: [246.953] ms Wrote image file mandelbrot-serial.ppm [mandelbrot ispc]: [50.832] ms Wrote image file mandelbrot-ispc.ppm (4.86x speedup from ISPC)
Due to the reason that the ISPC compiler maps gangs of program instances to SIMD instructions executed on a single core. So we can know that the work is imbalance between each job.
Part II
Question 3.1
1 2 3 4 5 6 7 8 9
# ./mandelbrot_ispc -v 2 -t [mandelbrot serial]: [246.911] ms Wrote image file mandelbrot-serial.ppm [mandelbrot ispc]: [50.675] ms Wrote image file mandelbrot-ispc.ppm [mandelbrot multicore ispc]: [30.390] ms Wrote image file mandelbrot-task-ispc.ppm (4.87x speedup from ISPC) (8.12x speedup from task ISPC)
Question 3.2
We first look at mandelbrot_ispc_task, the idea of this function is easy, the whole procession is like mandelbrot_ispc. But with different tasks handle different areas.
foreach (j = ystart ... yend, i = 0 ... width) { float x = x0 + i * dx; float y = y0 + j * dy;
int index = j * width + i; output[index] = mandel(x, y, maxIterations); } }
Well, the answer is the max thread you CPU could support.
Question 3.3
Tasks are independent work that can be executed with different cores. Contrary to threads, they do not have execution context and they are only pieces of work. The ISPC compiler takes the tasks and launches how many threads it decides.
Program 4
Question 4.1
1 2 3 4 5 6
# ./sqrt [sqrt serial]: [1747.862] ms [sqrt ispc]: [366.439] ms [sqrt task ispc]: [38.224] ms (4.77x speedup from ISPC) (45.73x speedup from task ISPC)
Question 4.2
For this question, we should make sure that the load is balanced and time-consuming.
1 2 3
for (unsignedint i=0; i<N; i++) { values[i] = 2.99f; }
1 2 3 4 5 6
# ./sqrt [sqrt serial]: [2617.087] ms [sqrt ispc]: [396.478] ms [sqrt task ispc]: [45.276] ms (6.60x speedup from ISPC) (57.80x speedup from task ISPC)
Question 4.3
For this question, we should make sure that the load is imbalanced.
1 2 3
for (unsignedint i=0; i<N; i++) { i % 8 ? values[i] = 1.0f : values[i] = 2.99f; }
1 2 3 4 5 6
# ./sqrt [sqrt serial]: [132.275] ms [sqrt ispc]: [142.305] ms [sqrt task ispc]: [16.307] ms (0.93x speedup from ISPC) (8.11x speedup from task ISPC)
Program 5
Question 5.1
1 2 3 4
# ./saxpy [saxpy ispc]: [21.670] ms [13.753] GB/s [1.846] GFLOPS [saxpy task ispc]: [22.282] ms [13.375] GB/s [1.795] GFLOPS (0.97x speedup from use of tasks)
I think in this question, we should use less tasks, due to the cache line the CPU writes, if there are many tasks, we would always meet a cache miss. So I change the task to be 2.
However, when I change the task to be 2, there is no speedup improvement, so the reason maybe the memory bandwidth.
1 2 3
[saxpy ispc]: [21.400] ms [13.927] GB/s [1.869] GFLOPS [saxpy task ispc]: [23.430] ms [12.720] GB/s [1.707] GFLOPS (0.91x speedup from use of tasks)
Question 5.2
The reason is in Question 5.1. Put the content in the cache line and flash the cache line.