int numNodes = num_nodes(g); double equal_prob = 1.0 / numNodes; #pragma omp parallel for for (int i = 0; i < numNodes; ++i) { solution[i] = equal_prob; }
double* tempArray = newdouble[g->num_nodes];
bool converged = false; while (!converged) { #pragma omp parallel for default(none) shared(tempArray, g) for (Vertex v = 0; v < g->num_nodes; ++v) { tempArray[v] = 0.0; }
#pragma omp parallel for default(none) shared(tempArray, g, solution) for (Vertex v = 0; v < g->num_nodes; ++v) { for (const Vertex* iv = incoming_begin(g, v); iv != incoming_end(g, v); ++iv) { tempArray[v] += solution[*iv] / static_cast<double>(outgoing_size(g, *iv)); } }
#pragma omp parallel for default(none) shared(tempArray, g, damping, numNodes) for (Vertex v = 0; v < g->num_nodes; ++v) { tempArray[v] = tempArray[v] * damping + (1.0 - damping) / static_cast<double>(numNodes); }
double t = 0.0; #pragma omp parallel for default(none) reduction(+: t) shared(solution, g, numNodes, damping) for (Vertex v = 0; v < g->num_nodes; ++v) { if(outgoing_size(g, v) == 0) { t += damping * solution[v] / static_cast<double>(numNodes); } }
#pragma omp parallel for default(none) shared(tempArray, g, t) for (Vertex v = 0; v < g->num_nodes; ++v) { tempArray[v] += t; }
double globalDiff = 0.0; #pragma omp parallel for default(none) reduction(+: globalDiff) shared(tempArray, solution, g) for (Vertex v = 0; v < g->num_nodes; ++v) { globalDiff += abs(tempArray[v] - solution[v]); }
#pragma omp parallel for default(none) shared(tempArray, solution, g) for (Vertex v = 0; v < g->num_nodes; ++v) { solution[v] = tempArray[v]; } converged = globalDiff < convergence; }
delete[] tempArray; }
Part 2
Top Down BFS
The easiest idea for implementing top-down bfs is to use two variables, one is for the current frontier, and another is for the next frontier. And when we add the new node to the next frontier, we should use #pragma omp critical to protect the next frontier. However, this method is too slow.
However, we could let each thread use its local next frontier. Thus we could avoid critical section and make the code faster.
int start_edge = g->outgoing_starts[node]; int end_edge = (node == g->num_nodes - 1) ? g->num_edges : g->outgoing_starts[node + 1];
// attempt to add all neighbors to the new frontier for (int neighbor=start_edge; neighbor<end_edge; neighbor++) { int outgoing = g->outgoing_edges[neighbor]; if (distances[outgoing] == NOT_VISITED_MARKER && __sync_bool_compare_and_swap(&distances[outgoing], NOT_VISITED_MARKER, distances[node] + 1)) { int index = localList[omp_get_thread_num()].count++; localList[omp_get_thread_num()].vertices[index] = outgoing; } } }
int totalCount = 0; for (int i = 0; i < omp_get_max_threads(); ++i) { count[i] = totalCount; totalCount += localList[i].count; } frontier->count = totalCount;
// Parallel copy the data from `localList` to `frontier` #pragma omp parallel for for (int i = 0; i < omp_get_max_threads(); ++i) { memcpy(frontier->vertices + count[i], localList[i].vertices, localList[i].count * sizeof(int)); } }
Bottom Up BFS
The Top Down BFS is an easy job to do actually. Because it is a prior algorithm. However, in the code, we would do many logical operations especially the frontier size is large and its ancestors’ size is small. Look at the following code snippet, which would cause so many logical operations.
1 2 3 4 5
if (distances[outgoing] == NOT_VISITED_MARKER && __sync_bool_compare_and_swap(&distances[outgoing], NOT_VISITED_MARKER, distances[node] + 1)) { int index = localList[omp_get_thread_num()].count++; localList[omp_get_thread_num()].vertices[index] = outgoing; }
I think the paper is enough. So I omit detail here. You should carefully read the paper. And I record some information here.
The majority of the computational work in BFS is checking edges of the frontier to see if the endpoint has been visited. The total number of edge checks in the conventional top-down algorithm is equal to the number of edges in the connected component containing the source vertex, as on each step every edge in the frontier is checked.
Well, at now the bottom-up way is clear. For every step, we just traverse all the vertices. And we have the current frontier information. From Top Down BFS, we need to check for every vertex’s neighbor to add it to the next_frontier. In the Bottom Up BFS, we just find whether the child is the ancestor of the vertices in the frontier. Thus every child would only can be visited once.
// Swap the pointer bool * temp = next; next = current; current = temp;
} delete[] frontier; delete[] new_frontier; }
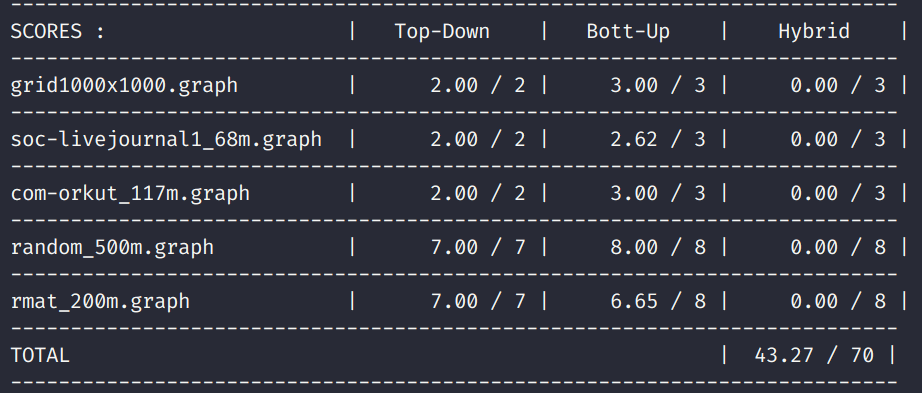
However, the result is illustrated below.
As you can see, I cannot get the full grades. I am wondering the reason. You could look at this article.
And the article provides some tips:
Avoid writing to global data that is accessed from multiple threads.
Align shared global data to cache line boundaries.
Don’t store temporary, thread specific data in an array indexed by th thread id or rank.
When parallelizing an algorithm, partition data sets along cache lines, not across cache lines.
The last tip is what we could do. So we could use schedule(dynamic, chunk_size) for openMP to improve efficiency.
Hybrid BFS
The pairing of the top-down approach with the bottom-up approach is complementary, since when the frontier is its largest, the bottom-up approach will be at its best whereas the top-down approach will be at its worst, and vice versa.
So the idea is simple. Uses the Top Down BFS for steps when the frontier is large. We begin each search with the Top Down BFS and continue until the frontier becomes too large, at which point we switch to the Bottom Up BFS.
voidbfs_hybrid(Graph graph, solution* sol) { // A flag bool isUpDownBFS = true; bool switchFlag = true;
// Set up for Bottom Up BFS int chunk_size = MACHINE_CACHE_LINE_SIZE * 16; while (graph->num_nodes < omp_get_max_threads() * chunk_size) { chunk_size /= 2; } bool *frontier_bottom_up_bfs = newbool[graph->num_nodes]; bool *new_frontier_bottom_up_bfs = newbool[graph->num_nodes]; bool *current = frontier_bottom_up_bfs; bool *next = new_frontier_bottom_up_bfs; #pragma omp parallel for for (int i = 0; i < graph->num_nodes; ++i) { current[i] = false; } current[ROOT_NODE_ID] = true;
// Set up for Top Down BFS vertex_set list; vertex_set_init(&list, graph->num_nodes); int maxThreadNum = omp_get_max_threads(); vertex_set localList[maxThreadNum]; #pragma omp parallel for for(int i = 0; i < maxThreadNum; ++i) { vertex_set_init(&localList[i], graph->num_nodes); } int count[maxThreadNum]; vertex_set* frontier_top_down_bfs = &list; frontier_top_down_bfs->vertices[frontier_top_down_bfs->count++] = ROOT_NODE_ID;
// Global configuration #pragma omp parallel for // initialize all nodes to NOT_VISITED for (int i=0; i<graph->num_nodes; i++) sol->distances[i] = NOT_VISITED_MARKER; sol->distances[ROOT_NODE_ID] = 0;
uint frontier_length = 1;
while (frontier_length != 0) { if (isUpDownBFS) { // We come from Bottom Up BFS if (!switchFlag) { #pragma omp parallel for for (int i = 0; i < maxThreadNum; ++i) { vertex_set_clear(&localList[i]); } // We need to copy the information from `current` // to the `frontier_top_down, it is trivial. #pragma omp parallel for for (int i = 0; i < graph->num_nodes; ++i) { if (current[i]) { int index = localList[omp_get_thread_num()].count++; localList[omp_get_thread_num()].vertices[index] = i; } } int totalCount = 0; for (int i = 0; i < omp_get_max_threads(); ++i) { count[i] = totalCount; totalCount += localList[i].count; } frontier_top_down_bfs->count = totalCount; #pragma omp parallel for for (int i = 0; i < omp_get_max_threads(); ++i) { memcpy(frontier_top_down_bfs->vertices + count[i], localList[i].vertices, localList[i].count * sizeof(int)); } switchFlag = true; }
#pragma omp parallel for for (int i = 0; i < maxThreadNum; ++i) { vertex_set_clear(&localList[i]); } top_down_step(graph, frontier_top_down_bfs, localList, count, sol->distances); frontier_length = frontier_top_down_bfs->count; if (frontier_length != 0 && graph->num_nodes / frontier_length< UP_THRESHOLD) { isUpDownBFS = false; } } else { // We come from Top Down BFS if (switchFlag) { // We should first clear the `current` because it has // some dirty data. #pragma omp parallel for for (int i = 0; i < graph->num_nodes; ++i) { current[i] = false; } // Transfer the information from `frontier_top_down_bfs` to // `current`. It is easy for converting from Top Down BFS to // Bottom Up BFS #pragma omp parallel for for (int i = 0; i < frontier_top_down_bfs->count; ++i) { current[frontier_top_down_bfs->vertices[i]] = true; } switchFlag = false; } #pragma omp parallel for for (int i = 0; i < graph->num_nodes; ++i) { next[i] = false; } frontier_length = bottom_up_step(graph, current, next, sol->distances, chunk_size); bool * temp = next; next = current; current = temp; if (frontier_length != 0 && graph->num_nodes / frontier_length > BOTTOM_THRESHOLD ) { isUpDownBFS = true; } }