缓存基础知识
Contents
通用的缓存组织结构
缓存的目的在于减少CPU直接从内存中读取数据的次数。缓存是静态存储器,其不需要对电容进行刷新的性质决定了其访问速度必然快于动态存储器(内存)。如何构建内存与缓存之间的映射关系是缓存的一个最重要的基础知识。对于开发者来说,缓存的存在是透明的。然而,当编写高性能计算或者多线程的程序时,我们不能忽视缓存这个在计算机体系结构中起到重要作用的部件。
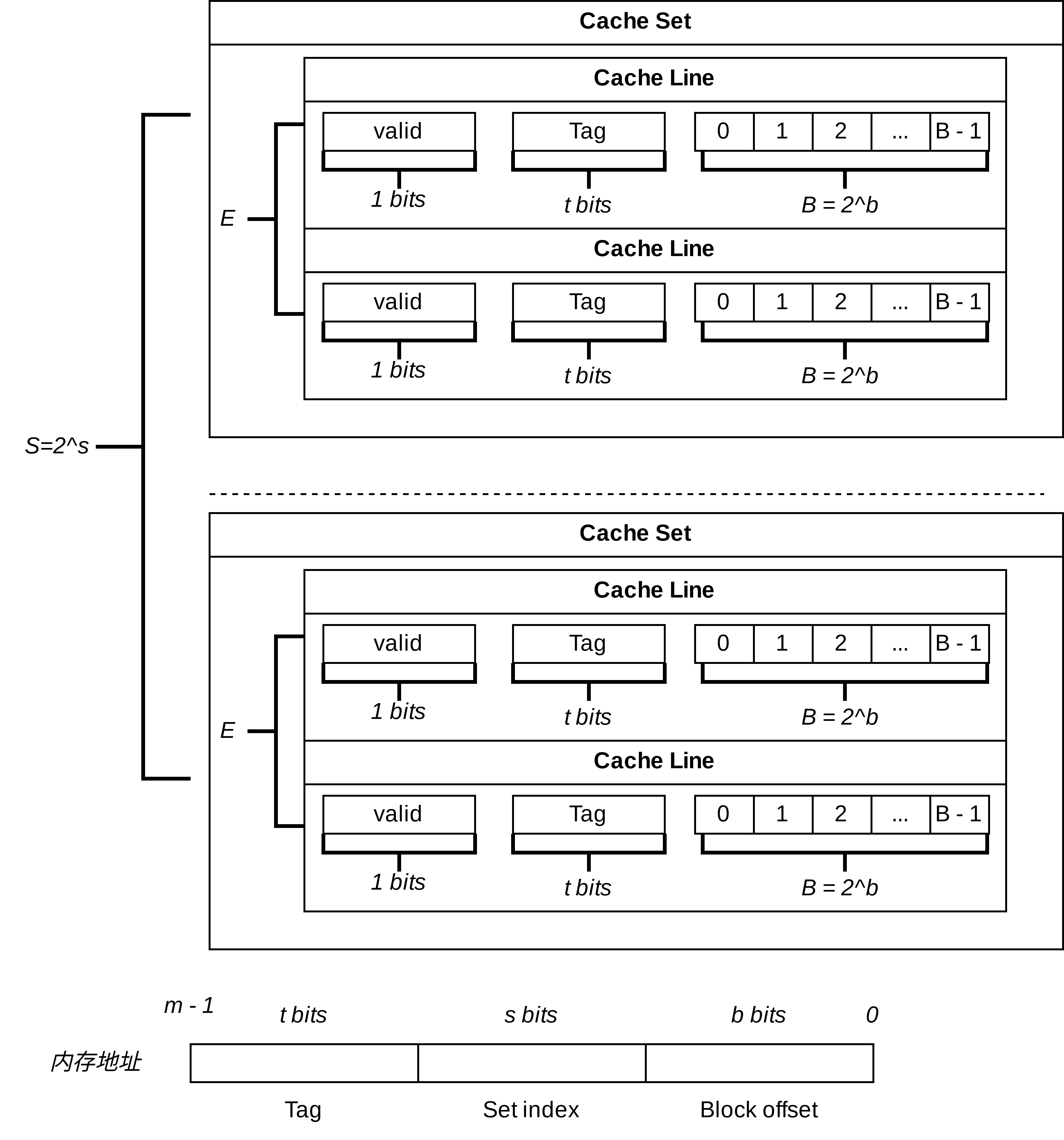
我们假定某个计算机支持$m$位的内存地址。显然,常见的$m$为32位或者64位。如下图所示,缓存是由多个cache set组成的,每个cache set由多个cache line组成,同时每一个cache line包含一个cache block。我们定义如下的符号含义:
- $S$:cache set的数目。
- $E$: 每一个cache set所包含的cache line的数目。
- $B$: 每一个cache line所包含的cache block的总字节。

我们需要根据当前的内存地址,首先定位到cache set,由于cache set的数目为$S$,故我们需要$s$位数来定位到某个cache set(显然,$2^{s} = S$)。同时,我们需要$b$位数来定位到cache block的偏移量(显然,$2^{b} = B$)。此时,我们还有一个问题没有解决,我们仍然需要判断其位于哪个cache line中。我们在前两个过程中已经使用了$s + b$位,故我们可以使用剩下的$t = m - (s + b)$位来去定位cache line。然而,目前的缓存组织结构中并不存在这个信息,所以我们需要在缓存中添加。同时,我们在cache line中添加一个标志位,判断当前cache line是否有效,如下图所示:
直接映射缓存(Direct-Mapped caches)
当$E = 1$时,就被称为直接映射缓存,其原理就相当简单了。由于每一个cache set只包含一个cache line,所以每一个地址有且只能有一个cache line与之对应。然而,这样在某些情况下会带来很大的性能问题。举个例子,如下面的代码所示,我们循环地依次在地址$A$和地址$B$中写入数据。恰好不好,地址$A$的地址$B$的$s$是一致的。显然,他们会访问到同一个cache set,由于只有一个cache line,每次其对比tag值都不相同,故缓存硬件会从内存中读取相应的数据放到cache line中,导致每次cache line中的数据都会被刷新,也就是一直cache miss。这种现象被称为cache颠簸(cache thrashing)。
1 | int main(int argc, char *argv[]) { |
组相连缓存(Set Associative Caches)
为了解决上述问题,每一个cache set可以含有多个cache line,假如$E = 2$,对于上述例子而言,硬件会寻找两个cache line的tag值是否与物理地址的tag相等,这样就在一定程度上可以缓解cache颠簸。然而,这样也带了另一个问题,如果没有一个cache line与之对应,产生了cache miss。那么缓存必须换出一个cache line(如果有空的cache line,当然就直接使用了)。显然,这就回到了常见的换入换出策略了,例如LRU或者LFU。
全相连缓存
当$S = 1$时,即只存在一个cache set时,我们直接舍弃了$s$。然而,我们增大了寻找cache line的成本,意味着需要遍历来找到我们所需的cache line,如果是cache miss的情况,我们甚至需要遍历所有的cache line。当然,硬件可能提供一些并行来加快速度,然而由于极高的硬件成本,采用率极少。
缓存写策略
- write-through: 同时写入缓存和内存。其优势在于能够始终保持内存和缓存的一致性,劣势在于每次写CPU都会调用一次写内存操作,浪费时钟。
- write-back: 先写入缓存,后面再写入内存。每个cache line中会有一个bit位记录数据是否被修改过,称之为dirty bit。优势在于避免了写内存操作,然而劣势在于需要处理不一致性。
write-allocate
当使用write-back时,write-allocate通常一起被使用,CPU将数据写入内存的情况,如果缓存未命中其总是被写入缓存中。
参考资料
- Cache的基本原理
- CSAPP Chapter 6
- UNIX Systems for Modern Architectures Chapter 2