多核处理器带来的缓存一致性问题
Contents
在前面的章节中,我们介绍了缓存的底层实现。我们一直假设计算机只有一个CPU核心,然而在现代的计算机体系结构中,CPU拥有多个核心。为了简单起见,如下图所示,每个核心都有一块独立的私有缓存,以及一个由所有核心共享的末级缓存(LLC)。
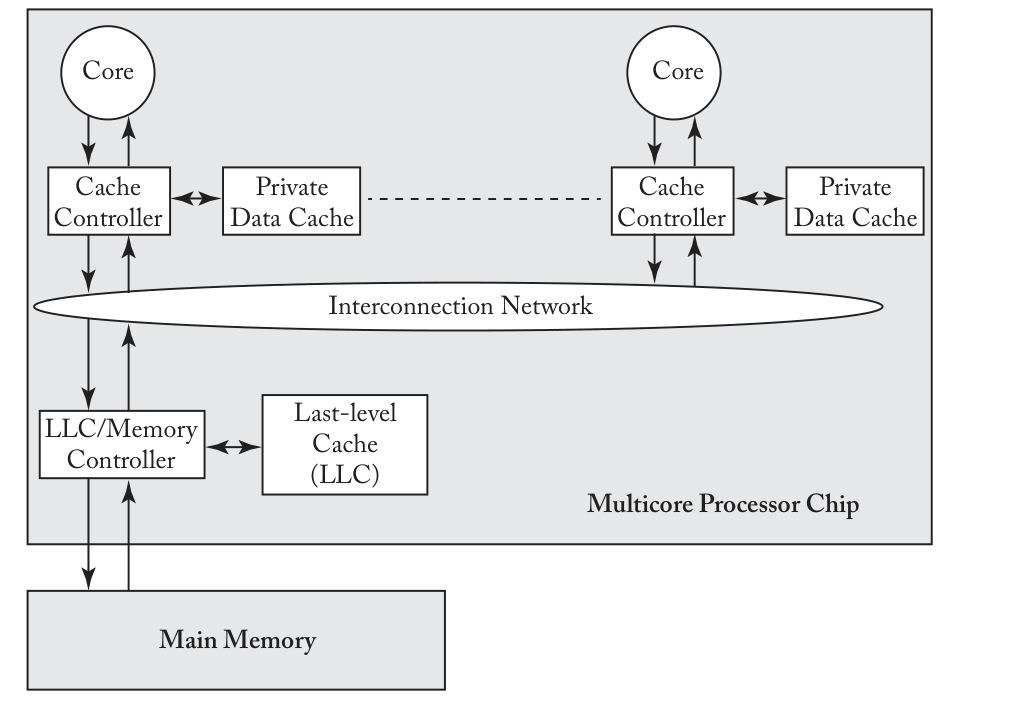
缓存一致性问题
假设我们运行一个进程,其有两个线程,一个线程运行在C1,另一个线程运行在C2。从程序员的观点出发,这段代码是相当简单的。然而,我们需要从缓存的角度思考这个问题。
1 |
|
如下表所示:
- Time 1时刻,对于C1来说,其需要对地址A写入值43,由于缓存未命中,其会将A的值42写入其私有缓存中。对于C2来说,其需要检查地址A的内容,由于缓存未命中,其会将A的值42写入其私有缓存中。(可能读者会想如果采取的write-through策略,C2有可能会读取到43的值,我们在这个例子中忽略这种情况,实际上如果涉及到两个核同时读写,write-through策略也会导致缓存的不一致性)
- Time 2时刻,C2继续进行循环操作,由于其能命中其私有缓存,故其一直会进行死循环,然而实际上A的值应该是43。
| Time | Core C1 | Core C2 |
|---|---|---|
| 1 | S1: A=43; | L1:while(A == 42); |
| 2 | L2:while(A == 42); | |
| 3 | L3:while(A == 42); | |
| 4 | … | |
| n | Ln:while(A == 42); |
从上述的过程可以得出一个重要的结论,多核问题会产生新的缓存不一致问题。由于私有缓存的存在,当某两个私有缓存指向的是同一个物理地址时,需要保持同步,维护一致性。
一致性问题解决通用方法
从上述的例子,我们其实可以很快地可以类比在多线程编程中的读写同步问题。当只读的时候,不存在不一致性问题,问题就在于写入缓存时。在实际的处理器中采用了cache coherence protocol,分为两类:
- Consistency-agnostic coherence:首先需要将写入的这个事件通过缓存中的内部网络传递到其它核,再写入缓存。
- Consistency-directed coherence:先写入缓存,再广播事件,常用于GPGPU。
(Consistency-agnostic)缓存一致性不变量
我们能够确定一个十分明确的不变量,single-writer-multiple-reader(SWMR),如下图所示,对于任一时刻,对于某一个内存地址来说,其要么有多个核心在执行读操作,要么只有一个核心在进行读写操作。

同时我们还需要确保数据的一致性,内存位置的值与其最后一个读写时期结束时的值相同。因此我们可以明确如下的两个缓存一致性不变量:
- Single-Writer, Multiple-Read (SWMR) Invariant.
- Data-Value Invariant.
通用实现方法
我们希望所有CPU的私有缓存以及所有核心共享的末级缓存都能够维持缓存一致性不变量。目前采用的通用方式就是对于每一个私有缓存以及所有核心共享的末级缓存通过添加一个coherence controller状态机来维持这两个不变量。
对于私有缓存的coherence controller,特称为cache controller,其需要处理来自CPU的Load/Store请求,当是Load请求的时候返回相应的数据给CPU。同时其需要发送请求和响应,接收其他controller的请求和响应。对于末级缓存而言,特称为memory controller,其只需要发送请求和响应,接收其他controller的请求和响应。
在后面的所有讨论中,我们都默认cache策略为write-back。
一个简单协议的实现
首先,对于状态机而言,我们必须定义状态以及导致状态变化的事件:
- 对于cache controller的每一个cache block而言,其有三种状态,$\text{I}$(invalid),$\text{V}$(valid), $\text{IV}^{\text{D}}$。最后一个状态的存在是由于需要从内存里面读取到缓存,我们必须考虑stall的影响。
- 对于memory controller的每一个cache block而言,其只有两种状态,$\text{I}$(invalid),$\text{V}$(valid)。
- 当状态为$\text{I}$时,所有的cache controller相对应的cache block状态都为$\text{I}$。
- 当状态为$\text{V}$时,有且只有一个cache controller对于的cache block状态为$\text{V}$。
- 三类主要事件:
- Get:请求一个cache block。
- DateResp:传输cache block里的数据。
- Put:将cache block里的数据写回内存。
我们可以给出如下图所示的状态转换:
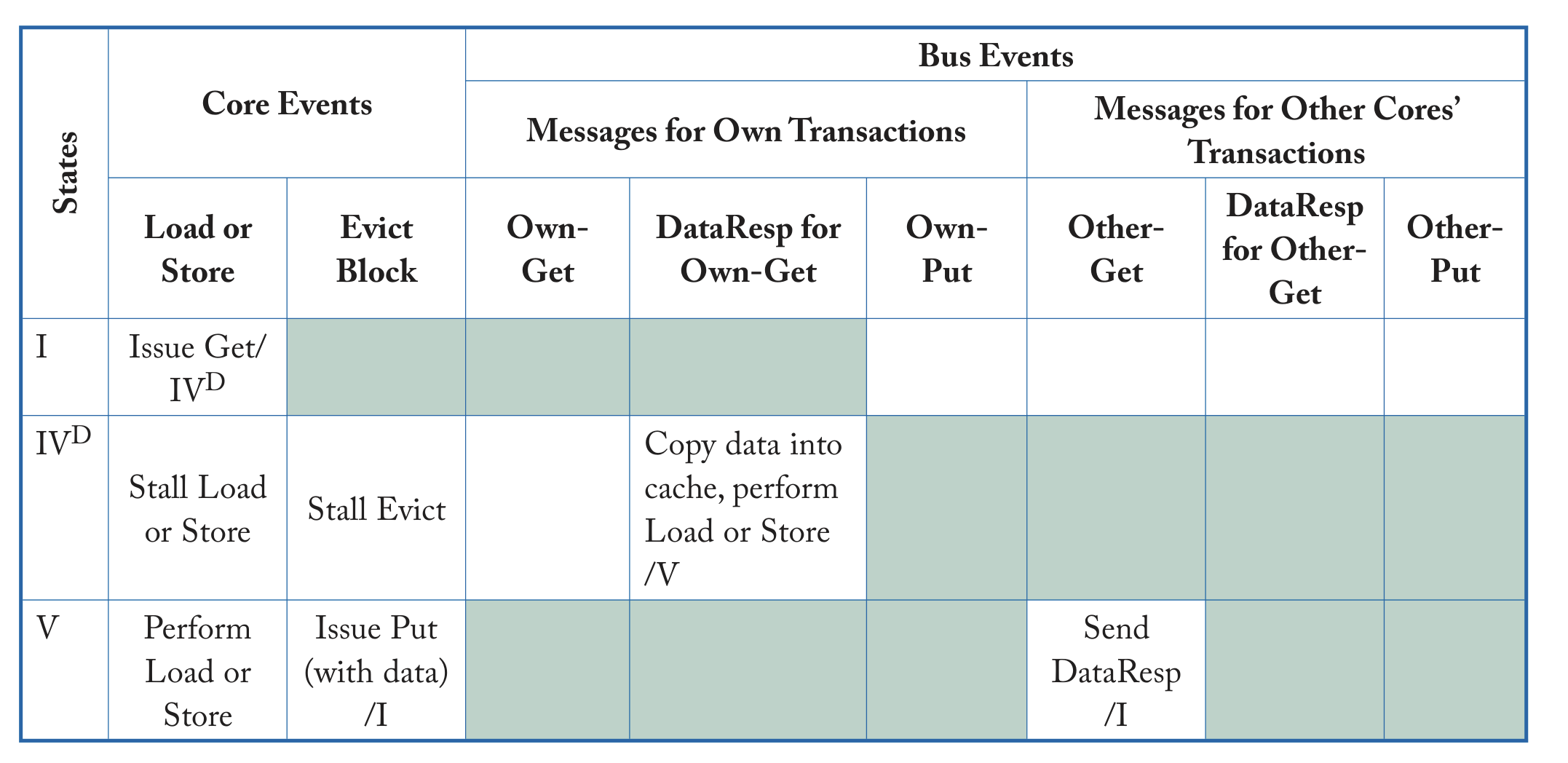

可以发现这个协议的实现效率十分地低,实际上我们完全在多核处理器下实现的串行操作,在使用当某几个核心竞争相同的cache block时,会发生大量的stall,导致性能的降低。
设计缓存一致性协议的通用思路
状态
在多核系统中,缓存的状态定义变得尤为关键,为了提高效率实现共享不能简单地将其状态划分为invalid和valid:
- Validity:一个valid的cache block必须是其包含了最新的数据。
- Dirtiness:Dirtiness一定是暗含了Validity。当cache block的状态发生变化时,其必须把结果写入到内存中。
- Exclusivity:同样Exclusivity一定时暗含了Validity,且其是唯一一个拥有memory block的副本。
- Ownership:是当前memory block的所有者,负责控制其响应和请求。
Stable states
- $\text{M}$(modified):valid,exclusive,owned and potentially dirty。
- $\text{O}$(owned):valid,owned,and potentially dirty but not exclusive。对于这种状态而言,cache block仅仅是只读的,其他核心的cache block也可能共享这个数据,但是其并不拥有控制权,所有的请求和响应都需要是$O$的coherence controller来处理。
- $\text{E}$(exclusive):valid,exclusive,and clean。
- $\text{S}$(shared):valid but not exclusive,not dirty and not owned。
- $\text{I}$(invalid):可以理解为Nothing。
Transient states
我们定义如下的规则,对于$\text{XY}^{\text{Z}}$而言,其意味着只有经历完事件$\text{Z}$,才能完成状态$\text{X}$到$\text{Y}$的转换。
Transactions
我们定义如下的transactions:
- GetShared(
GetS):将block变为$\text{S}$状态。 - GetModified(
GetM):将block变为$\text{M}$状态。 - Upgrade(
Upg):将block从$\text{S}$或者$\text{O}$状态变为$\text{M}$状态。 - PutShared(
PutS):从$\text{S}$状态释放block。 - PutExclusive(
PutE):从$\text{E}$状态释放block。 - PutOwned(
PutO):从$\text{O}$状态释放block。 - PutModified(
PutM):从$\text{M}$状态释放block。
同时我们可以知道CPU会对cache controller发送如下的事件:
- Load:如果缓存命中了,直接读取,否则执行
GetS。 - Store:如果在$\text{M}$或者$\text{E}$状态下命中了缓存,直接写入缓存,否则执行
GetM或者Upg。 - Atomic read-modify-write:如果在$\text{M}$或者$\text{E}$状态下命中了缓存,直接执行RMW语义,否则执行
GetM或者Upg。 - Instruction fetch:如果缓存命中了,直接读取,否则执行
GetS。 - Replace:执行
PutS,PutE,PutO或者PutM。
参考资料
- A Primer on Memory Consistency and Cache Coherence chapter 2 and chapter 6