It’s hard to implement Matrix-Matrix Multiplication. So I recommend the following repository for you. I also refer to this repository when doing this assignment.
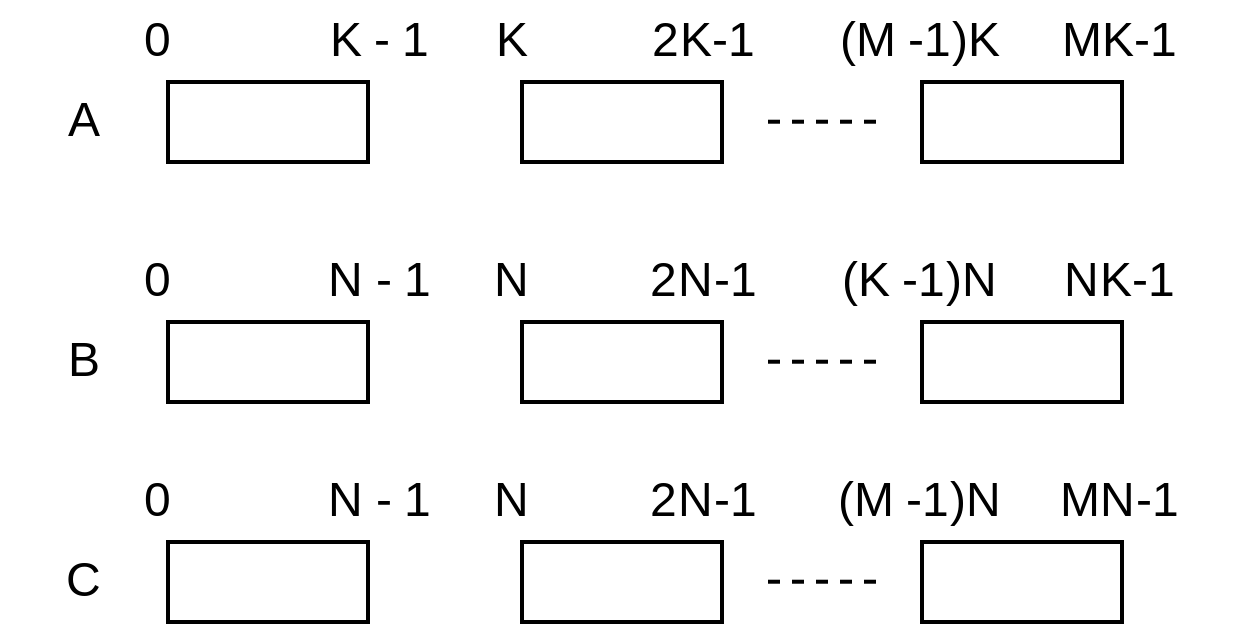
We do not use 2-D array, we flat the array to one dimension. We assume that $A$ is $M \times K$, $B$ is $K \times N$, and $C$ is $M \times N$. We need to implement the $\alpha A \times B + \beta \times C$.
/** * @brief Calculate the GEMM sequentially * * @details The matrix A, B, C are all one-dimensional array, so the need * to find the way to calculate the matrix multiplication. * */ staticvoidgemm(int m, int n, int k, double *A, double *B, double *C, double alpha, double beta){ for (int i = 0; i < m; i++) { for (int j = 0; j < n; j++) { double inner_pod = 0; for (int kk = 0; kk < k; kk++) { inner_pod += A[i * k + kk] * B[kk * n + j]; } C[i * n + j] = alpha * inner_pod + beta * C[i * n + j]; } } } };
voidgemm(int m, int n, int k, double *A, double *B, double *C, double alpha, double beta){ Gemm::gemm(m, n, k, A, B, C, alpha, beta); }
We assume that $A$ is $1024 \times 1024$ and $B$ is $1024 \times 1024$, we could see that the Intel mkl library would only execute 18ms, the reference implementation would execute 62ms. However, the native implementation executes 5746ms.
Blocked matrix multiplication
The efficiency is low because we do not use the cache. So the idea is use the blocked matrix multiplication thus improving the cache hit rate. The idea is intuitive. If you’are not familiar with the blocked multiplication, I recommend you to read some materials.
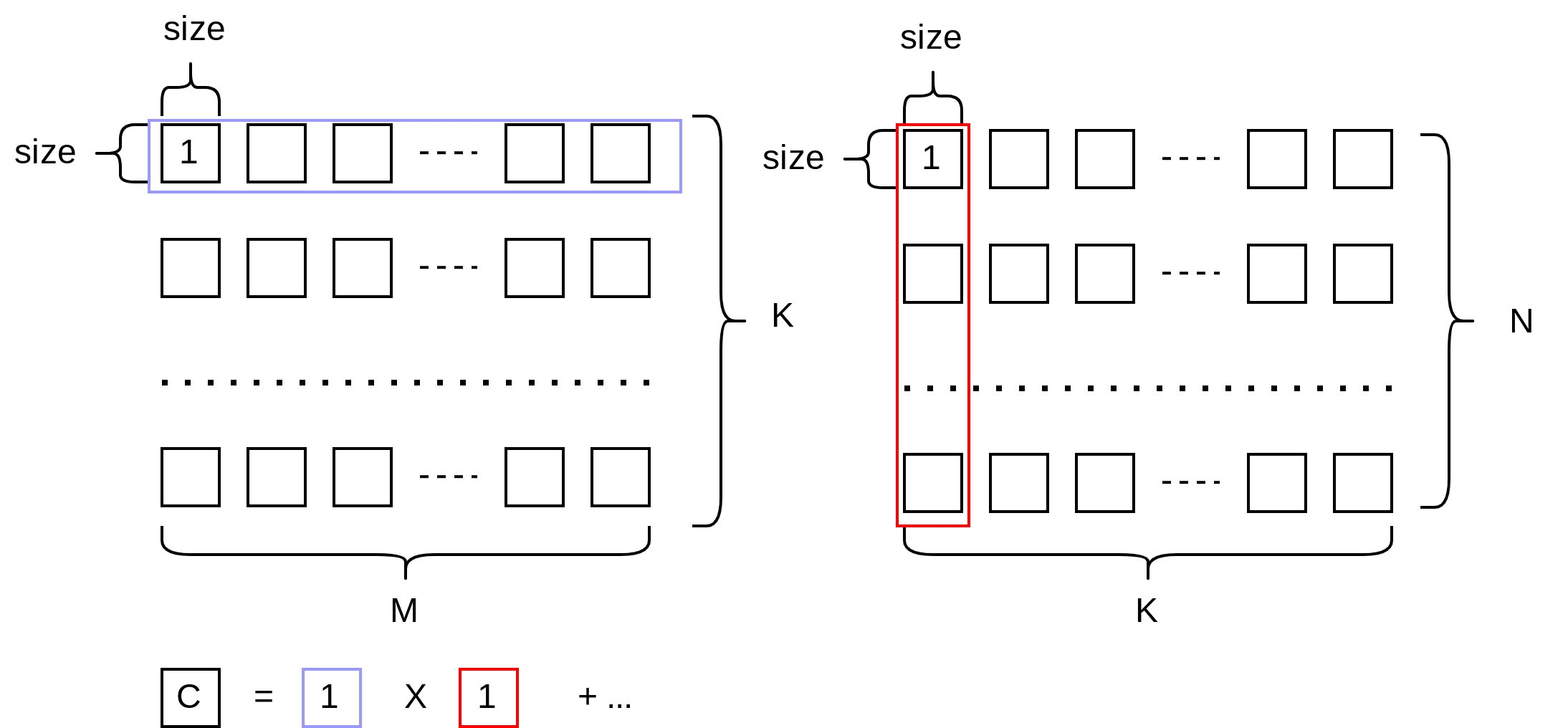
From the below figure, we first need to split the matrix into the blocked matrices. We assume each block would be the $size \times size$. For $A$, we first need to split for the row $M$. And for $B$, we need to split for the col $N$. And for both $A$ and $B$, we could simultaneously handle $K$. However, the trouble is that we need to know each block top-left coordinate, because we need to find the absolute position. So we should define the coordinates for the absolute position.
1 2 3 4 5 6 7 8 9
/** * @brief A wrapper to wrap the coordinates for indicating the * start left-top point for the current blocked matrix. * */ structPoint2D { int i{}; /**< The absolute i */ int j{}; /**< The absolute j */ };
So we need to first split for $M$ and for $N$, then for $K$, we could get the following incomplete c++ code:
1 2 3 4 5 6 7
for (int i = 0; i < m; i += size;) { for (int j = 0; j < n; j += size;) { for (int kk = 0; kk < k; k += size) { ... } } }
In the first loop, we should set the $A$’s start point of i and we also need to tell whether i + size < m. Similarly, in the second loop, we should set the $B$’s start point of j and we also need to tell whether j + size < n. In the last loop, we should set the $A$’s start point of j and $B$’s start point of i and also need to tell whether k + size < kk.
It’s easy to calculate the start points of $C$. It is dependent on the i and j. Thus we could have the following code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
Point2D a{}, b{}, c{}; constint size = 6; for (int i = 0; i < m; i += size) { int mBlock = i + size < m ? size : m - i; a.i = i; c.i = i; for (int j = 0; j < n; j += size) { b.j = j; c.j = j; int nBlock = j + size < n ? size : n - j; for (int kk = 0; kk < k; kk += size) { a.j = kk; b.i = kk; int kBlock = kk + size < k ? size : k - kk; } } }
/** * @brief Apply the C = beta C, it should be calculated at first. * */ staticvoidscalarMultiplication(int mBlock, int nBlock, int n, Point2D &c, double *C, double beta){ for (int i = 0; i < mBlock; i++) { for (int j = 0; j < nBlock; j++) { C[(i + c.i) * n + (j + c.j)] = beta * C[(i + c.i) * n + (j + c.j)]; } } }
/** * @brief Matrix multiplication with block * * @details In order to implement the block matrix multiplication, we need * to calculate the blocked matrix A and blocked matrix B. For example * A11 A12 B11 B12 C11 C12 * A21 A22 B21 B22 C21 C22 * C11 = A11 X b11 + A12 X B21 * */ staticvoidmatrixMultiplicationBlock(int mBlock, int nBlock, int kBlock, int n, int k, Point2D &a, Point2D &b, Point2D &c, double *A, double *B, double *C, double alpha){
for (int i = 0; i < mBlock; i++) { for (int j = 0; j < nBlock; j++) { double inner_pod = 0; for (int kk = 0; kk < kBlock; kk++) { inner_pod += A[(i + a.i) * k + (kk + a.j)] * B[(kk + b.i) * n + (j + b.j)]; } C[(i + c.i) * n + (j + c.j)] += alpha * inner_pod; } } }
/** * @brief Split the matrix * */ staticvoidgemmUsingBlock(int m, int n, int k, double *A, double *B, double *C, double alpha, double beta){ Point2D a{}, b{}, c{}; constint size = 6; for (int i = 0; i < m; i += size) { int mBlock = i + size < m ? size : m - i; a.i = i; c.i = i; for (int j = 0; j < n; j += size) { b.j = j; c.j = j; int nBlock = j + size < n ? size : n - j; scalarMultiplication(mBlock, nBlock, n, c, C, beta); for (int kk = 0; kk < k; kk += size) { a.j = kk; b.i = kk; int kBlock = kk + size < k ? size : k - kk; matrixMultiplicationBlock(mBlock, nBlock, kBlock, n, k, a, b, c, A, B, C, alpha); } } } }
staticvoidgemm(int m, int n, int k, double *A, double *B, double *C, double alpha, double beta){ gemmUsingBlock(m, n, k, A, B, C, alpha, beta); } };
Then executing ./gemm 1024. As the result shows, we execute 843ms. It is much better than the native implementation.
Blocked matrix multiplication with memory layout change
We can still improvement the efficiency, we still access the matrix $B$ with col. However, when the matrix size is big, it would cause cache miss. When executing ./gemm 2048. The program would cause 7476ms. This is because the memory layout of $B$ is bad for cache hit. So we could change the layout of $B$.
staticvoidscalarMultiplication(int mBlock, int nBlock, int n, Point2D &c, double *C, double beta){ for (int i = 0; i < mBlock; i++) { for (int j = 0; j < nBlock; j++) { C[(i + c.i) * n + (j + c.j)] = beta * C[(i + c.i) * n + (j + c.j)]; } } }
staticvoidmatrixMultiplicationBlock(int mBlock, int nBlock, int kBlock, int n, int k, Point2D &a, Point2D &b, Point2D &c, double *A, double *B, double *C, double alpha){
for (int i = 0; i < mBlock; i++) { for (int j = 0; j < nBlock; j++) { double inner_pod = 0; for (int kk = 0; kk < kBlock; kk++) { inner_pod += A[(i + a.i) * k + (kk + a.j)] * B[(j + b.i) * n + (kk + b.j)]; } C[(i + c.i) * n + (j + c.j)] += alpha * inner_pod; } } }
staticvoidgemmUsingBlock(int m, int n, int k, double *A, double *B, double *C, double alpha, double beta){ Point2D a{}, b{}, c{}; constint size = 6; for (int i = 0; i < m; i += size) { int mBlock = i + size < m ? size : m - i; a.i = i; c.i = i; for (int j = 0; j < n; j += size) { b.i = j; c.j = j; int nBlock = j + size < n ? size : n - j; scalarMultiplication(mBlock, nBlock, n, c, C, beta); for (int kk = 0; kk < k; kk += size) { a.j = kk; b.j = kk; int kBlock = kk + size < k ? size : k - kk; matrixMultiplicationBlock(mBlock, nBlock, kBlock, n, k, a, b, c, A, B, C, alpha); } } } }
staticvoidgemm(int m, int n, int k, double *A, double *B, double *C, double alpha, double beta){
double *newB = newdouble[n * k];
for (int j = 0; j < n; j++) { for (int i = 0; i < k; i++) { newB[j * k + i] = B[i * n + j]; } }
gemmUsingBlock(m, n, k, A, newB, C, alpha, beta);
delete[] newB; } };
Then executing ./gemm 1024. As the result shows, we execute 478ms. We gain more performance.
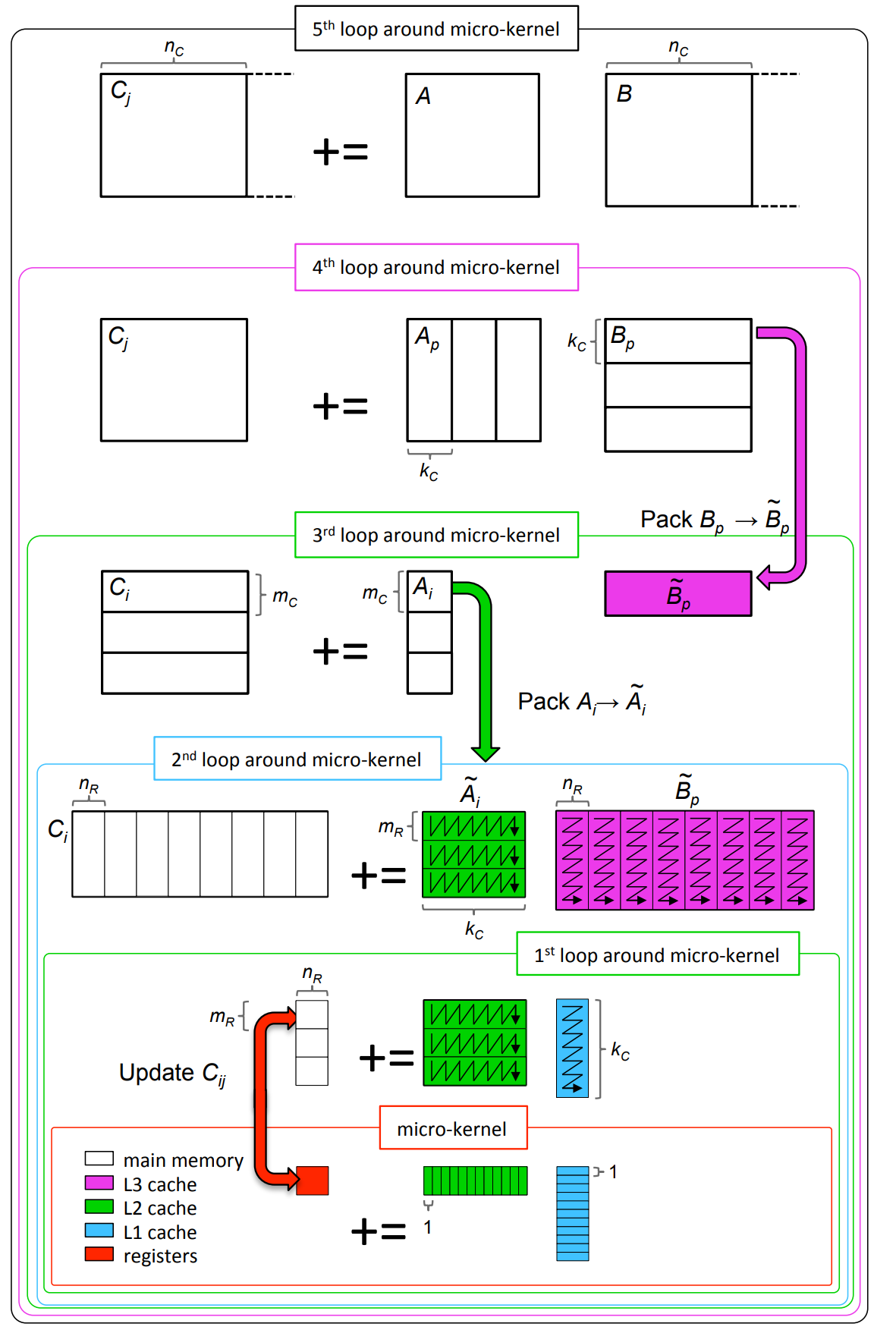
Blocking for multiple levels of cache
It’s hard to explain this idea, you should carefully read the blislab tutorial and read the following paper carefully:
classGemmBlockWithThreeCacheLevel { public: /** * @brief Disable constructing this class * */ GemmBlockWithThreeCacheLevel() = delete;
staticvoidmatrixMultiplicationBlock(int mBlock, int nBlock, int kBlock, int n, int k, Point2D &a, Point2D &b, Point2D &c, double *A, double *B, double *C, double alpha){
for (int i = 0; i < mBlock; i++) { for (int j = 0; j < nBlock; j++) { double inner_pod = 0; for (int kk = 0; kk < kBlock; kk++) { inner_pod += A[(i + a.i) * k + (kk + a.j)] * B[(j + b.i) * k + (kk + b.j)]; } C[(i + c.i) * n + (j + c.j)] += alpha * inner_pod; } } }
/** * @brief Use five loop tp calculate the matrix-matrix multiplication, for * simplicity here, I only implement C = alpha AB. * */ staticvoidgemmUsingBlock(int m, int n, int k, double *A, double *B, double *C, double alpha, double beta){
// We need to create pack A and pack B. It's a bad idea to allocate // memory in the loop. double *packedA = newdouble[sizeM * sizeK]; double *packedB = newdouble[sizeN * sizeK];
for (int j = 0; j < n; j += sizeN) { // In this loop, we only handle for the matrix B, it would // be split up by `sizeN` for the col. b.j = j; c.j = j; int nBlock = j + sizeN < n ? sizeN : n - j;
for (int kk = 0; kk < k; kk += sizeK) { // In this loop, we handle for the matrix A and matrix B. // For the matrix A it would be split up by `sizeK` for the col // For the matrix B it would be split up by `sizeK` for the row a.j = kk; b.i = kk; int kBlock = kk + sizeK < k ? sizeK : k - kk;
// At here, we should pack the B into a consecutive memory, in // order to improve the cache hit rate and avoid TLB miss. We make // `packedB` into the L3 cache, So the L3 size should be greater // than the `sizeN * sizeK`. So in the following `for` loop all // the access to the `packedB` would gain great efficiency. And we // will convert the row-major to the col-major.
for (int i = 0; i < m; i += sizeM) { // In this loop, we handle for the matrix A, it would be split // up by the `sizeI` for the row. a.i = i; c.i = i; int mBlock = i + sizeM < m ? sizeM : m - i;
// At here, we should pack the A into a consecutive memory, in // order to improve the cache hit rate and avoid TLB miss. We // make `packedA` into the L2 cache, so the L2 cache must be // greater than `sizeM * sizeK`. So the following `for` loop // for accessing to the `packedA` would get great efficiency. for (int i_ = 0; i_ < mBlock; i_++) { for (int j_ = 0; j_ < kBlock; j_++) { packedA[i_ * sizeK + j_] = A[(a.i + i_) * k + (a.j + j_)]; } }
// Here, we already split the matrix A and matrix B into the block. // However, we need to split again just like the above, this would // be super easy. for (int jr = 0; jr < nBlock; jr += rSizeN) { int rNBlock = jr + rSizeN < nBlock ? rSizeN : nBlock - jr; rb.i = jr; rc.j = jr + c.j;
for (int ri = 0; ri < mBlock; ri += rSizeM) { int rMBlock = ri + rSizeM < mBlock ? rSizeM : mBlock - ri; ra.i = ri; rc.i = ri + c.i;